Convolutional dictionary learning
So we saw convolutions. Given a filter and a sparse code , an important insight we saw from the convolution is that the sparse code plays the role of an "indicator", indicating where and how much the filter should appear in the convolution .
Let's leverage this intuition a bit further. What if we have a signal , and that we try to "approximate" using a sum of convolutions, i.e.,
for which we can visualize as
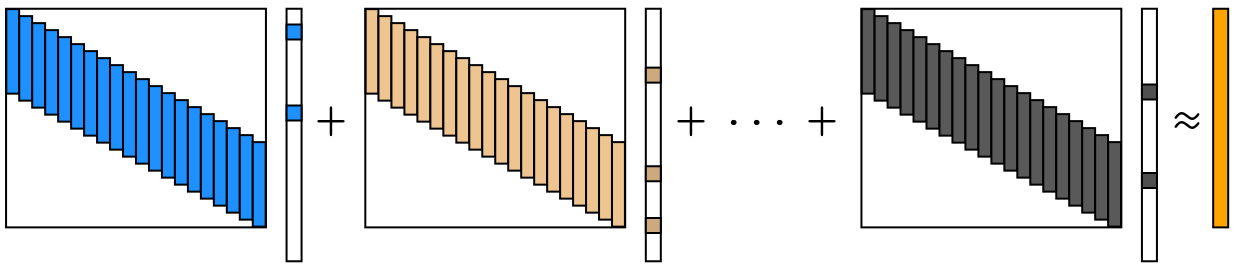
where the orange vector on the right is the signal . Let's formalize this as an optimization problem (single signal case):
i.e., we want to find the best filters and the sparse code to represent the signal . The hyperparameter balances the trade-off between data fitting loss and the sparsity of , and we enforce the constraint to avoid the scaling ambiguity in between the filters and the sparse code. We can easily extend this to the case where we have multiple signals:
The problem formulation of (2) and (3) is called a convolutional dictionary learning (CDL) problem. So what's the advantage of formulating the problem as a CDL?
CDL is highly interpretable:
In CDL, each signal is approximated by a sparse linear combination of the filters and the sparse code. The sparse code indicates where and how much the filters should appear.
Minimizing the CDL objective we obtain specialized filters representing the frequently occurring patterns in the signals.
Equation (1) also shows that CDL is a distributed representation. There's a particular name for this representation: it is a sparse representation — the model uses a sparse linear combination of the filters and the sparse code to describe each signal in the dataset.
This work is licensed under CC BY-SA 4.0. Last modified: July 09, 2026.
Website built with Franklin.jl and the Julia language.